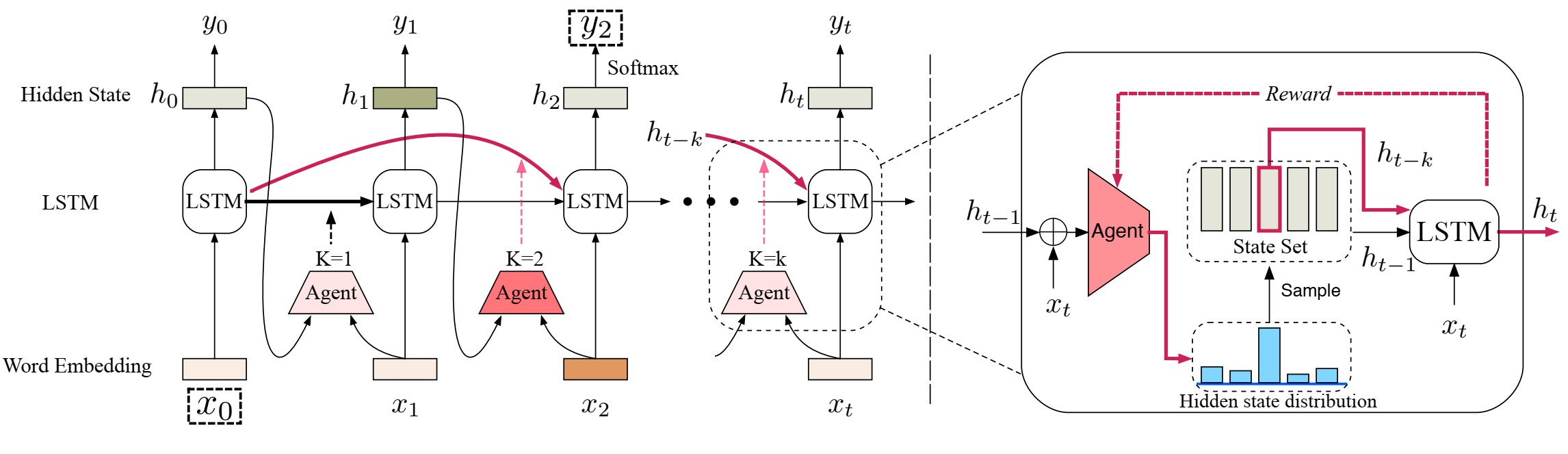
引入动态跳边机制来减轻LSTM 在长距离依赖问题上表现欠缺的问题,该动态跳边机制能够学会直接连接两个有依赖关系的词语。
由于在训练数据中,并没有依赖关系的标注信息,我们提出一种新的基于强化学习方法从数据中自动学习依赖关系。